配套软件版本:V9及更低 集搜客网络爬虫软件 新版本对应教程:V10及更高 数据管家——增强版网络爬虫 的对应教程是《自动选择下拉菜单采集数据—以知网为例》 注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登录集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。 一、操作步骤 用中国知网的期刊为例,展示连续动作中选择动作和爬虫路线中翻页的组合。本次教程要实现的是先检索2016年发表的期刊,再对检索结果进行采集,流程如下图所示:
为了实现这个,需要建立两级规则,第一级规则通过连续动作来自动选择发表年份,第二级规则负责采集期刊内容和翻页。操作步骤如下:
二、案例规则+操作步骤
第一步:定义第一级规则抓取内容
1.1,加载页面 打开集搜客网络爬虫,输入想要采集的样本网址并按Enter键,看到浏览器加载出网页后,点击右上方的“定义规则”。 注意:这里的截图和文字说明都是集搜客网络爬虫版本。如果您安装的是火狐插件版,那么就没有“定义规则”按钮,而是应该运行MS谋数台。 1.2,输入主题名 在工作台“主题名”处输入第一级规则的主题名,再点击“查重”,提示“该名可以使用”,就可以继续,否则请重新命名。这里命名主题名为“中国知网期刊检索前”。 Tips:虽然这一级规则主要是为了做选择动作,但为了保证页面已经加载完成,连续动作可以顺利进行,通常在这级规则建立一些抓取内容。 1.3,内容映射
选择“期刊”作为抓取内容,双击期刊,在弹出的标签栏处输入关键内容,整理箱命名为检索前,并勾选为关键内容。直观标注的基础操作在这里不赘述,不懂的请参考教程《采集网页数据》。 第二步:定义第一级规则连续动作
2.1,输入目标主题名 点击“连续动作”工作台,输入目标主题名(也就是第二级规则的主题名,这里命名为“中国知网期刊检索后”),点击“谁在用”,弹出的窗口没有信息,说明这个主题名没有被占用,可以继续后面的操作,否则就需要换一个主题名。 2.2,创建第一个连续动作——起始年份选择2016
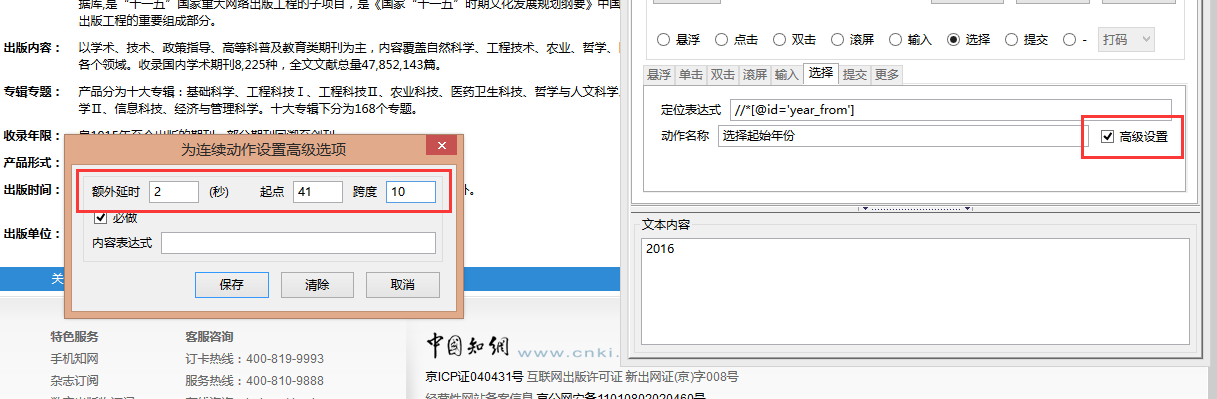
2.2.1,找到定位表达式,填写动作名称 点击新建,选择动作类型为“选择”,点击一下起始年份,会自动定位到相应节点,选择“显示XPath:偏好id”,程序会自动显示对应的Xpath路径,再点击搜索,可以看到这个路径能找到唯一的节点,可作为动作的定位表达式,将这个路径复制到定位表达式处,在动作名称写上文字,是为了方便清楚每个动作的用处。 Tips:选择类型的连续动作,定位表达式必须写到下拉菜单的select节点,而不能写到某一个选项的option节点,否则运行时会报错。 2.2.2,高级设置
我们需要实现的是采集2016年发表的期刊,所以需要在起始年份和终止年份都选择点击2016年,这就需要在连续动作的高级设置里做约束。
2.3,创建第二个连续动作——终止年份选择2016
点击新建,选择动作类型为“选择”。参考步骤2.2找到终止年份对应的Xpath路径,并在高级设置中设置额外延时为2秒,起点为3(2016在第3个option),跨度填100。 2.4,创建第三个连续动作——点击检索
点击新建,选择“提交”动作。参考步骤2.2找到“检索”对应的Xpath路径,并在高级设置中设置额外延时为2秒。 2.5,存规则 点击“存规则”按钮保存已完成的第一级规则。 第三步:定义第二级规则抓取内容
3.1,新建规则 点击“定义规则”恢复到普通网页模式,选择2016年并点击检索搜索出文献结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,弹出提示“工作台上有内容,清空吗?”,点击确定。 输入主题名,这里的主题名就是上一级规则的连续动作那里填写的目标主题名,也就是“中国知网期刊检索后”,点击查重,弹出提示“该名已被预定。可编辑:是”,说明这个主题名可以使用。 3.2,标注要采集的信息
在页面直接点击要采集的内容,弹出的窗口填上名称,给“标题”勾上关键内容,并做上样例复制。点击测试可以预览采集内容。直观标注的详细说明在这里不赘述,详细可参考教程《采集列表数据》。 第四步:定义第二级规则翻页线索
4.1,设置翻页线索 点击爬虫路线,点击“新建”,选择“记号线索”;找到翻页标记“下一页”对应的节点,右击-线索映射-记号线索;找到包含整个翻页区域并且有class值或id值的节点,右击-线索映射-定位-线索1。设置翻页的操作在这里不赘述,详细可参考教程《设置翻页采集》。 4.2,存规则 点击“存规则”按钮保存已完成的第二级规则。 第五步:抓数据 连续动作的两级规则是连贯执行的,所以只需要运行第一级规则,做完动作后程序会自动调用第二级规则。直接运行第二级规则就会报错,因为打开的是执行动作前的初始页面。
5.1,打开打数机,找到第一级规则的主题名,点击“单搜”或“集搜”,可以看到打数机的网页窗口会自动选择2016年,并不断往下翻页。 5.2,打开第二级主题的文件夹查看结果数据,在xml文件的actionvalue字段记录了选择的条目,这样就能与结果数据一一对应起来。 上篇文章:《连续动作:自动搜索关键词采集信息》 下篇文章:《连续动作:滚屏采集瀑布流网页》
若有疑问可以或
 |