可视化免编程
web如同一个大型的大数据库,其中包含各种各样有价值的信息,当您需要把某些特定信息采集下来,却往往可能面临这样的困境:
- 没有系统学过Python、Ruby、PHP、Perl、Javascript、java这些编程语言,通过写代码实现数据采集难度太大。
- 网络爬虫、网页抓取软件虽然很多,但学习难度大,初学者难以上手。
集搜客GooSeeker与“技术小白”共同成长。秉承此宗旨,集搜客GooSeeker网络爬虫软件操作简单,完全可视化操作,无需编程基础,熟悉电脑操作即可轻松掌握:
- 当定义采集规则时,用鼠标点选的方式,告知集搜客软件哪些是要抓取的内容,系统会即刻自动生成抓取规则;
- 当程序进行采集时,集搜客高仿真模拟真人操作,可以实现输入查询条件、点击链接、点击按钮等,还能通过设定调度参数,友好访问目标网站,避免给对方造成压力负担;
整个采集过程所见即所得,遍历的链接信息、抓取结果信息、错误信息等都会及时地反映在软件界面中。让您整个操作清晰明了,带着轻松的心情完成自己的任务。
通用网络爬虫
集搜客GooSeeker网络爬虫与其它网络爬虫相比,在易用性方面已经远远胜出,加上一键启动网络爬虫这个独特性功能和快捷采集工具的支撑,已经大大降低了对用户的技术基础条件的要求。然而,网页抓取毕竟是一个技术工作,需要适当掌握HTML等基础知识。也就是说需要花费一些时间学习这个软件的使用方法。既然已经有所投入(即便是时间上的),那么网络爬虫的通用性高低显得十分重要。
集搜客网络爬虫历经超过10年的行业历练,采用功能强大的chrome浏览器内核,所见即所得,不用网络嗅探器从底层分析网络通信消息,而是可视化定义抓取规则。
抓取范围可以归纳成如下几类:
- 各种网站类型:新闻、论坛、电商、社交网站、行业资讯、金融网站、企业门户等;
- 各种网页类型:服务器侧动态页面、浏览器侧动态页面(AJAX内容)、静态页面都可抓取,甚至可以抓取没有终点的瀑布流页面。
- 各种语言文字:不用特殊设置,自动支持所有语言编码,国际语言一视同仁;
可见,使用集搜客网络爬虫,整个互联网成为你的数据库!
不限深度不限广度
从网站上采集数据,尤其采集大型网站时,被采集的数据往往位于网站的不同层级的网页上,大大增加了网络爬虫采集数据的难度。百度或者google这样的综合网络爬虫,能够自动管理爬行的深度和广度。我们这里讨论的是聚焦网络爬虫,希望能够以尽量低的成本获得数据,而且希望只获取需要的网页内容。所谓聚焦,主要包含两方面:
- 所抓取的网页(无论深度还是广度)都是预先规划好的,不像综合网络爬虫那样自动去发现向深度和广度发展的新线索。可见,在受控范围内爬行必然会降低成本。
- 从网页上抓取的内容也是预先定义好的,这就是所谓的抓取规则。不像综合网络爬虫那样把整个网页文本内容都抓下来。可见,精确抓取可用于数据挖掘和情报分析,因为噪音已被精确地过滤掉了。
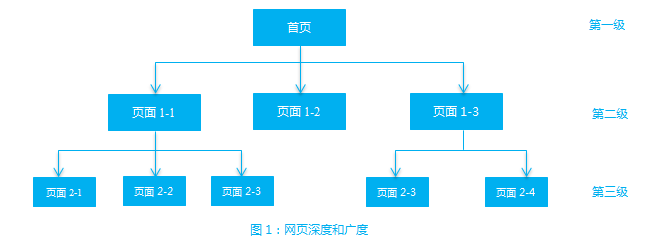
什么是网站深度和广度
在网站的信息架构中,有一种组织结构叫做树形结构:网站首页视为链接层级中第一级,与其有从属关系的页面视为链接层级中的第二级,一般称其为二级页面。通过二级页面又可以继续得到第三级页面,依此类推可以得到一个完整的树形链接结构。这样一个完整的链接结构,如图1所示。
在整个树形结构中,链接的层数被称为网页链接的【深度】(depth)。而在树形结构里,每层页面包含的页面总数被称为网页链接的【广度】(breadth)[1]。因此,图1中树形结构深度3,树形结构第三层的广度为5.
本地化存储保护著作权
集搜客GooSeeker的本地化存储机制,而且不提供采集结果发布手段,采集结果仅用于舆情监控、网民声音分析、内容分析、市场研究等,重视被抓取数据的著作权。体现在多方面:
- 集搜客把使用者的所有隐私信息存储在用户个人电脑上
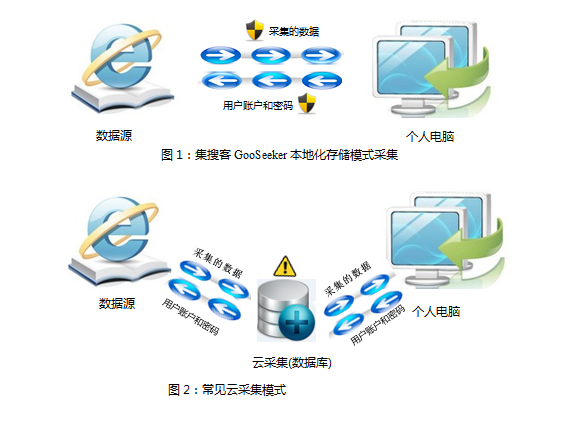
- 集搜客把所有采集结果数据直接存储在用户个人电脑上(如图1所示),便于用户对采集结果数据做各种数据挖掘和分析处理,而不是用于原样发布。
- 集搜客把采集任务放在用户个人电脑上运行,用户的采集数据行为别人是看不到的,所以,无论结果还是过程都得到了充分保护。同时本地运行采集任务也保证了高速、稳定和可靠。
相反,如图2所示,其他云采集方案要求用户必须把账号和密码先存储在大家都共享的云数据库,让云端的网络爬虫自动登录后执行采集,大大增加用户账户泄露的可能性,同时,云采集数据必需经过云服务器再到用户个人电脑,增加用户采集行为和结果数据被暴露的可能。
定时自启动采集
集搜客GooSeeker网页抓取软件可以设置定时自动采集,完全无需人工干预,自动采集最新数据,自动实现持续增量数据采集。比如
- 持续抓取论坛上的新发帖子;
- 持续抓取微博、twitter或者其它社交网站用户讨论。
- 持续跟踪在线商城的商品价格、用户评论;
- 在一个产品发布会前后,持续跟踪新闻的跟评,研究营销效果、用户对广告的态度、用户对品牌的态度
- 舆情监测需要实时自动抓取最新消息,才能掌握群众思想动态,做出正确舆论引导,提供分析依据。
- 商品比价需按照计划自动抓取商品价格,做出比较分析。
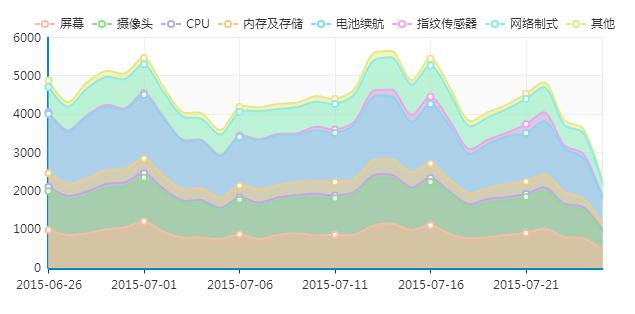
上图是手机消费者洞察系统中的一个截图,为了研究消费者品牌认知和态度,需要从互联网上采集所有用户评论信息,而且每天定时自动启动网络爬虫运行多次,把最新内容增量采集下来。




 粤公网安备44030502004363号
粤公网安备44030502004363号