《社交媒体的“钱”途,企业拥有一套社交媒体营销战略的意义》一文向读者展示企业的网络营销战略正在转变,早期的网络营销主要以广告为载体,经历了三个阶段:
Blogs
基于网络数据采集系统的社交媒体/网络营销
Mon, 01/11/2010 - 22:13 — Fuller- Fuller's blog
- Login to post comments
- Read more
基于Facebook电子邮件email挖掘的市场调研分析
Thu, 01/07/2010 - 10:05 — Fuller根据CNN科技新闻,Facebook最近进行了隐私策略调整,市场调研分析又增添了新手段:使用email(电子邮件)地址挖掘Facebook上的用户信息,获得极具价值的市场概况(marketing profiles)等商业情报信息,可以抓取的信息包括(受用户的隐私设置影响):名字、头像和其他图片、年龄、地区、兴趣、相片、消息板上的留言(wall posts)、朋友列表和名字,通过数据挖掘算法,可以扫描营销
- Fuller's blog
- Login to post comments
- Read more
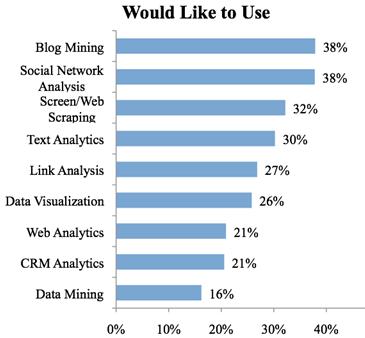
网页内容抓取在市场营销调研分析领域的地位走势
Tue, 01/05/2010 - 10:18 — Fuller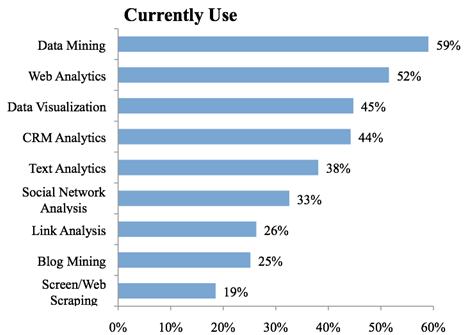
- Fuller's blog
- Login to post comments
- Read more
比较实体提取/识别(entity extraction)API
Mon, 01/04/2010 - 09:56 — Fuller看到某网友对比了多个实体识别/提取API,很有参考价值,摘录如下:
- Fuller's blog
- Login to post comments
- Read more
如何抓取AJAX动态页面
Sat, 12/26/2009 - 12:51 — Fuller笔者已经发表过多篇述及AJAX动态页面抓取原理的文章,本文将进行一次总结,首先,下面是以前文章的汇总:
- Fuller's blog
- Login to post comments
- Read more
增强AJAX/Javascript/JS网页文字抓取能力
Mon, 12/21/2009 - 23:40 — Fuller本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种AJAX网页文字的抓取方法:
- Fuller's blog
- Login to post comments
- Read more
路径名和文件名长度对网页内容提取软件的影响
Mon, 12/21/2009 - 22:38 — Fuller网页内容提取软件MetaSeeker将提取结果文件(XML文件)存储在本地目录DataScraperWorks下,主题名组成下一级子目录,在此子目录下存储网页内容提取结果文件,由于操作系统对一个目录下存储多少文件有限制,所以,在当提取结果文件很多时,会再建立一层子目录,名字是moreharvest,如果moreharvest子目录下文件又变得很多了,会再向下建立一层名字同样为moreharvest的子目录,缺省情况下,每级子目录中存
抽取手机游戏类别网页的超链接
Sun, 12/06/2009 - 17:25 — Fuller上一节讲了怎样扩展网络爬虫路线图,实际上是从广度上扩展网页数据抽取的范围,本来只抽取一类手机游戏数据,现在可以抽取12类游戏数据了,但是,至此,这12类游戏列表网页的超链接是通过定义12次信息结构实现的,虽然使用上节介绍的快捷方法可以在几分钟完成,但是,毕竟是手工创建了12个网页抽取线索,如果目标网站上的游戏类别变化了,用这些主题抽取网页数据时发现不了
- Fuller's blog
- Login to post comments
- Read more
抓取更多类手机游戏网页数据
Sun, 12/06/2009 - 15:06 — Fuller定义demo_list_game_basic主题时,我们选择了样本页面http://www.cn3gw.com/html/game/dongzuo/,我们继续研究这个网页的结构,我们看到两处分类列表(如图1 A和B)。分析以后,发现两个列表都导向相同的网页,但是网页的URL不太一样(实际上是一样,A使用网页URL的路径名,从而访问缺省的index.html页,而B使用完整的URL地址),选择A或者B都可以,但是,为了保持与demo_list_game_basic一致,我们选用A。
- Fuller's blog
- Login to post comments
- Read more
抓取手机游戏网页内容
Sat, 12/05/2009 - 11:19 — Fuller也许受此手机游戏网站的动作游戏所吸引,想为自己做一个手机动作类游戏搜索引擎或者仅仅是个简单的索引库,那么网页内容抓取软件工具包MetaSeeker就派上用场了,首先使用工具包中的MetaStudio工具定义抓取规则,从加载样本页面到生成游戏抓取规则,全部在MetaStudio图形化界面上操作,自动生成的内容抓取规则交给DataScraper,后者爬行网站并抓取
- Fuller's blog
- Login to post comments
- Read more
Copyright(c) 2007-2015, 深圳市天据电子商务有限公司. All Right Reserved.
粤ICP备11065265号-2
粤ICP备11065265号-2
X
