AJAX网页内容的获得一直是网站采集器头疼的事,同样对搜索引擎的网络爬虫来说一样头疼。用AJAX生成和管理网页内容除了为了达到提高用户体验的目标外,一个重要的目标是保护网站上的内容,防止被搜索引擎索引或者被采集。搜索引擎处之泰然,既然不让搜就不搜,然而网站采集器需要克服这个困难。
数据抽取
MetaSeeker在数据挖掘科研教学领域的贡献
Fri, 12/17/2010 - 21:50 — Fuller阅读了一篇第三届BiZ-WiZ杯华中地区大学生数学建模竞赛的优秀论文,参赛者使用MetaSeeker采集论坛信息,对论坛用户进行识别,识别出言论领袖、话题用户、活跃用户、关系圈等。该文被评为优秀论文,本人作为MetaSeeker的首席设计师,感到由衷的高兴。
- Fuller's blog
- Login to post comments
- Read more
怎样提高采集京东商城商品价格的速度
Sat, 11/27/2010 - 16:58 — Fuller在建设商品比价系统或者监测网络商城商品价格时,需要及时地采集最新的商品价格,尤其做价格监测竞争情报系统时,监测的频度要求很高。网站信息采集软件工具包MetaSeeker以精准采集著称,很适合做竞争情报采集系统,因此多个企业用户采用MetaSeeker建设商品比价和价格监测系统。
- Fuller's blog
- Login to post comments
- Read more
中信信用卡网络危机信息监测系统用做危机预防
Mon, 09/20/2010 - 15:12 — Fuller中国有句古话“千里之堤,溃于蚁穴”,警示我们小小的问题可能会酿成大危机,西方的海恩法则说了同样的道理,并强调对数据的跟踪和分析。
- Fuller's blog
- Login to post comments
- Read more
腾讯博客AJAX页面抓取技术讲解
Mon, 08/30/2010 - 10:33 — Fuller目前,大型博客一般都采用大量的AJAX技术,例如,展现博客评论时,用Javascript代码异步加载;又如,博文的点击数和回复数等元数据一般也用Javascript异步加载。页面抓取软件MetaSeeker具有很强的AJAX内容抓取能力,可以处理很多复杂情况,然而,MetaSeeker的可选配置项也很多,一时难于全面掌握。在此,我们讲解一个抓取腾讯博客内容的实例,展示怎样抓取AJAX异步加载的博文点击数。
- Fuller's blog
- Login to post comments
- Read more
怎样提高抓取网站数据的速度
Thu, 07/22/2010 - 21:37 — Fuller网站数据抓取软件MetaSeeker的设计理念跟其它网络爬虫有些不同,其中一个比较显著的区别是MetaSeeker将抓取到的某些网页地址URL永久保存,而且可以对其进行一些操作,例如,开放给在线版用户的操作有线索激活和去活,还可以使用周期性抓取指令重建线索。
- Fuller's blog
- Login to post comments
- Read more
怎样抓取跳转后的Web页面信息
Thu, 07/15/2010 - 15:22 — Fuller网页跳转基本上可以分成两种情形
- 利用HTTP消息的返回码和新网页地址进行跳转
- 在目标网页HTML中实现跳转。
Web页面信息抓取软件工具包MetaSeeker并不关心哪种跳转方式,都能进行信息抓取。但是,跳转后网页URL实际上已经改变了,在操作MetaStudio时需要注意几点。
采集京东商城网站的产品信息的技巧
Fri, 07/02/2010 - 15:04 — Fuller假设需要采集京东商城网站上的所有手机产品的信息,包括:商品名、价格、商品图片(MetaSeeker只采集图片网址)等信息。例如,样本网页:http://www.360buy.com/products/652-653-655-0-0-0-0-0-0-0-1-1-1.html。
- Fuller's blog
- Login to post comments
- Read more
怎样用MetaSeeker抓取新浪评论
Wed, 06/30/2010 - 18:43 — Fuller当前,一些大型社会性媒体(social media)网站(例如,博客、论坛、社交网)大量采用AJAX/Javascript,网页内容动态生成,而且同一个网页上的内容从多个信息源获得,这给网页信息抓取造成了障碍。下面以抓取新浪评论为例讲解怎样使用MetaSeeker抓取Ajax动态内容。现在,很多网站的新闻文章都允许评论,例如,新浪、搜狐、凤凰网等等,下面介绍的方法适用于其它类似网站。
- Fuller's blog
- Login to post comments
- Read more
举例说明什么是隐马尔科夫模型(HMM)
Mon, 06/07/2010 - 10:52 — Fuller什么是隐马尔科夫模型(HMM)
维基百科对隐马尔可夫模型的定义:
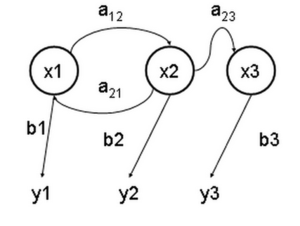
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
- Fuller's blog
- Login to post comments
- Read more
Copyright(c) 2007-2015, 深圳市天据电子商务有限公司. All Right Reserved.
粤ICP备11065265号-2
粤ICP备11065265号-2
X
