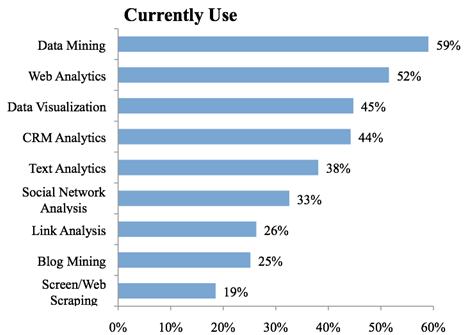
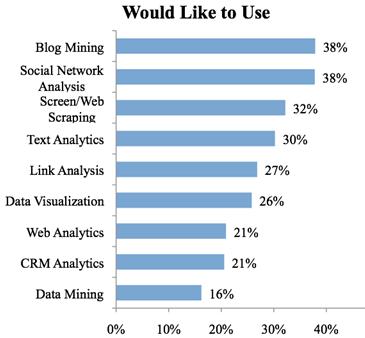
一般来说,比较狭义的观点认为数据挖掘区别于常规数据分析的关键点在于:
- 数据挖掘主要侧重解决四类问题:分类、聚类、关联、预测,
- 而常规数据分析则侧重于解决除此之外的其他数据分析问题:如描述性统计、交叉报表、假设检验等。
让我们来看两个例子对比:
一般来说,比较狭义的观点认为数据挖掘区别于常规数据分析的关键点在于:
让我们来看两个例子对比:
MPQA是一个语料库和观点识别系统(Corpus and Opinion Recogntion System)。根据其网页,该系统有下面几部分:
词性标注也叫词类标注,POS tagging是part-of-speech tagging的缩写。
维基百科对POS Tagging的定义:
《社交媒体的“钱”途,企业拥有一套社交媒体营销战略的意义》一文向读者展示企业的网络营销战略正在转变,早期的网络营销主要以广告为载体,经历了三个阶段:
根据CNN科技新闻,Facebook最近进行了隐私策略调整,市场调研分析又增添了新手段:使用email(电子邮件)地址挖掘Facebook上的用户信息,获得极具价值的市场概况(marketing profiles)等商业情报信息,可以抓取的信息包括(受用户的隐私设置影响):名字、头像和其他图片、年龄、地区、兴趣、相片、消息板上的留言(wall posts)、朋友列表和名字,通过数据挖掘算法,可以扫描营销
看到某网友对比了多个实体识别/提取API,很有参考价值,摘录如下:
笔者已经发表过多篇述及AJAX动态页面抓取原理的文章,本文将进行一次总结,首先,下面是以前文章的汇总: