Extract clues
Tools used: DataScraper, a Web data and clue extraction tool.
The following steps are taken to extract clues with DataScraper:
- Run DataScraper
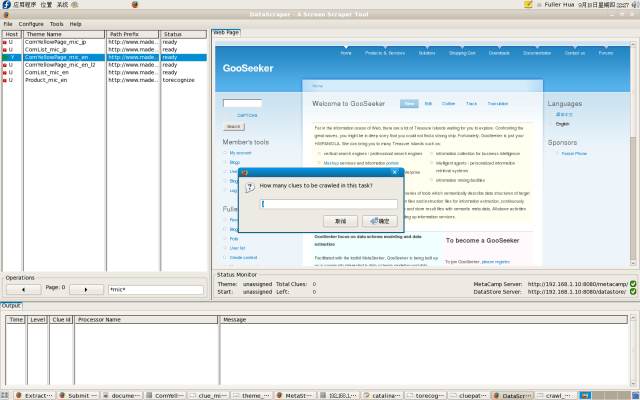
- Input the query condition "*mic*" to query matched themes;
- Select theme ComYellowPage_mic_en;
- Click right-button pop-up menu item Crawl over the theme list;
- Input the number of clues to be extracted for this theme. In this case, "1" is inputted.
Following figure show the GUI before submitting crawl command.
 Enlarge
Enlarge
After having extracted clues for commodity categories, the status of theme ComYellowPage_mic_en can be viewed via clicking right-button pop-up menu item Statistics.
What next
On most eCommerce sites or yellow page sites, all categories and all their sub-categories are listed on one single page so that all clues can be extracted from this page by running only one circle of data extraction work-flow. In contrast the tree-like data structure standing for the relation between a category and one of its sub-category is hard to be extracted because MetaStudio have only one type of bucket, i.e. ListBucket.
This sample site is an exception. Only top categories are listed on this page. Along a link for one category, a page containing the second level categories can be visited. As a result, the target theme of the clues extracted in current page is named as ComYellowPage_mic_en_l2 which means the theme for the second level categories. The steps to define clue extraction rules stated in this phase should be repeated once more for the new theme, which are stated in Appendix A.
After the sub-category pages having been extracted, a lot of clues belonging to theme ComList_mic_en are created, along which commodity lists can be extracted further. Phase 2 is to show how to extract commodity lists.
粤ICP备11065265号-2
