Extract data for competitive intelligence analysis
Despite the Web is an information and knowledge ocean, any piece of information doesn't float on the surface. Instead, they disperse here and there deeply so that they can only be found through diving, which is a great challenge. On the other hand, when a piece of information is retrieved, it may be viewed as being useless by one person. In contrast, it may be viewed as being great valuable by another person. To reveal the value behind a piece of information data mining should be performed effectively, which always provides an opportunity for the miner. MetaSeeker toolkits provide right ways and tools to confront challenges and to grasp opportunities. Following is an example on how to extract Web data for competitive intelligence analysis.
When surfing the Web, all kinds of advertisements annoy us all the way. In fact, a lot of competitive information can be mined from them. For example, what are to be communicated by advertisements from a competitor during a specific period? Where? Or, what advertisements are posted by same one competitor on different sites at the same time for the purpose of integrated marketing communications? and so on.
In order to provide information materials to competitive intelligence analysis, the data must be precisely extracted and be stored with semantic structure so that they can be fed into database or data warehouse of BI(business intelligence) platform. As you known, most of the popular BI platform can only manipulate structured data retrieved from database or data warehouse.
Extracting information on advertisements from the Web is not a straight-forward work since they are presented with complex presentation methods which are different from ordinary contents of HTML documents. For example, advertisements may be provided by 3rd parties and be loaded into HTML FRAMEs or IFRAMEs when the hosting pages are loaded. Or the advertisements are presented with the help of many Javascript codes. They are all obstacles for ordinary Web spiders to extract this kind of information. In contrast, MetaSeeker inherits all capabilities from the powerful Mozilla browser platform, which grants MetaSeeker great competitive strength.
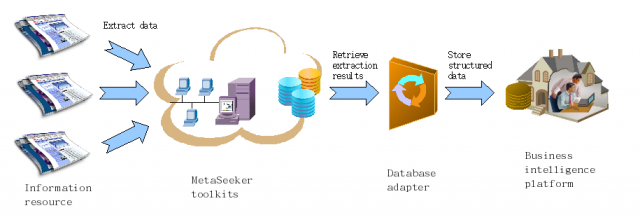
There are the following components:
- Multiple information resources: the information resources should be as many as possible to assure precise competitive intelligence analysis. In the past, cost to sample information increased sharply when more resources were involved. MetaStudio, a data schema definition tool, can define data extraction rules for a new resource in minutes, which cuts cost greatly for users.
- MetaSeeker toolkits: A cloud is depicted because MetaSeeker toolkits are always deployed distributedly in a network. The MetaSeeker toolkits extract advertisements from all resources. Different from ordinary Web spiders, MetaSeeker toolkits store the extraction results in XML files with semantic structures instead of HTML documents.
- Database adapter: The adapter retrieves extraction results from MetaSeeker's server, reformats the contents and feeds them into the database of the BI platform. The components in this type are from 3rd parties. We can recommend the most suitable one for a specific solution based upon successful cases.
- Business intelligence platform: the platform should be chosen by users at their will. A suitable database adapter can bridge MetaSeeker toolkits and the BI platform.
粤ICP备11065265号-2
